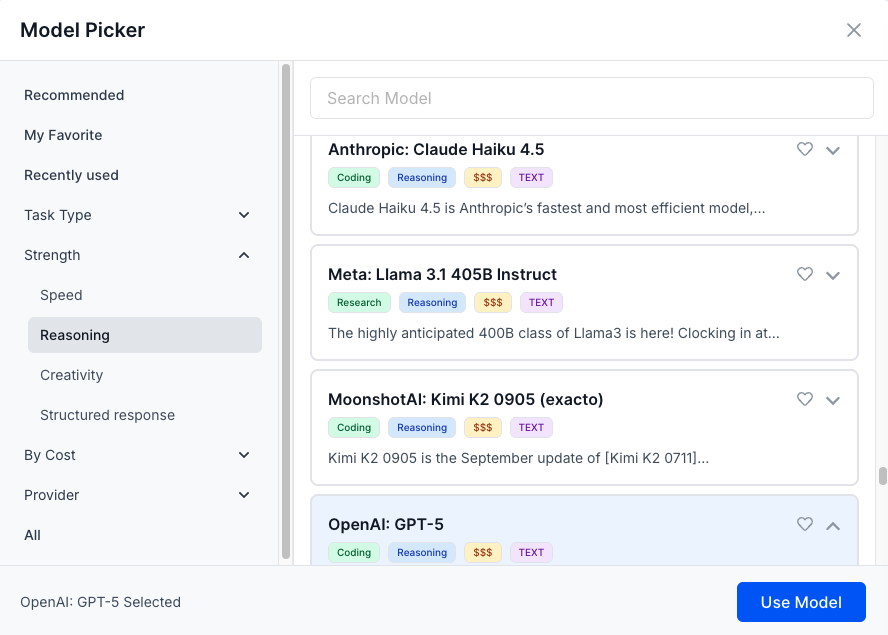








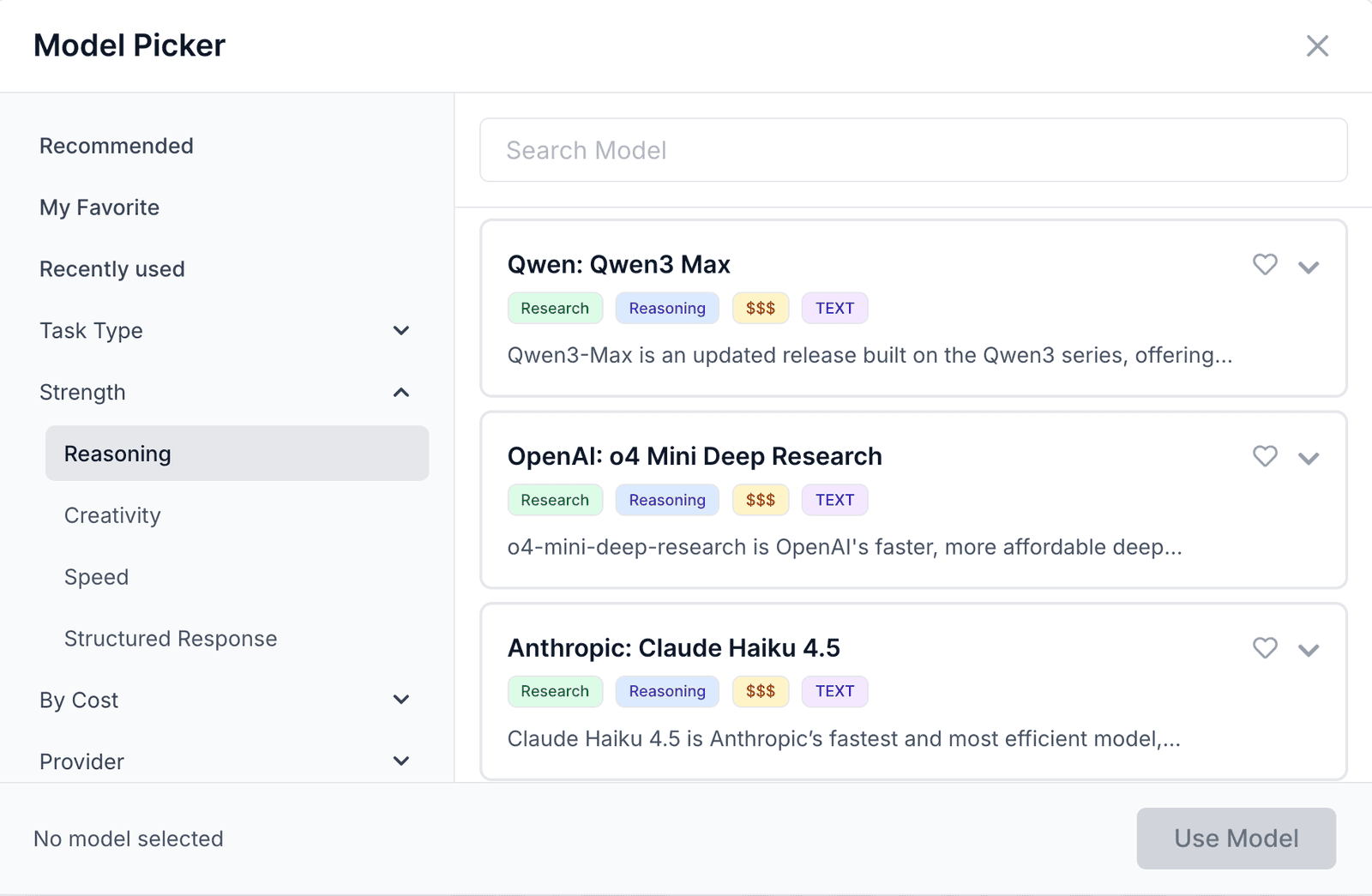
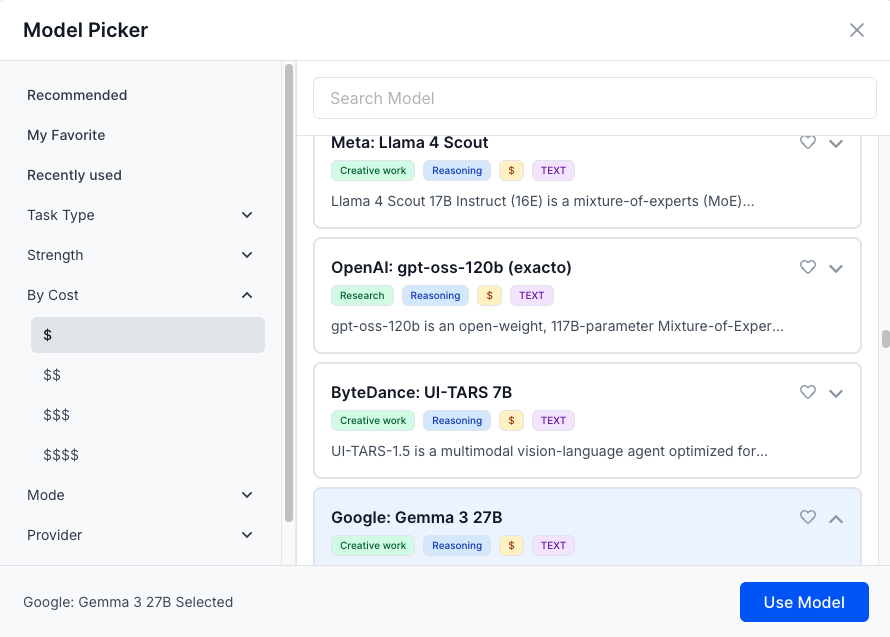
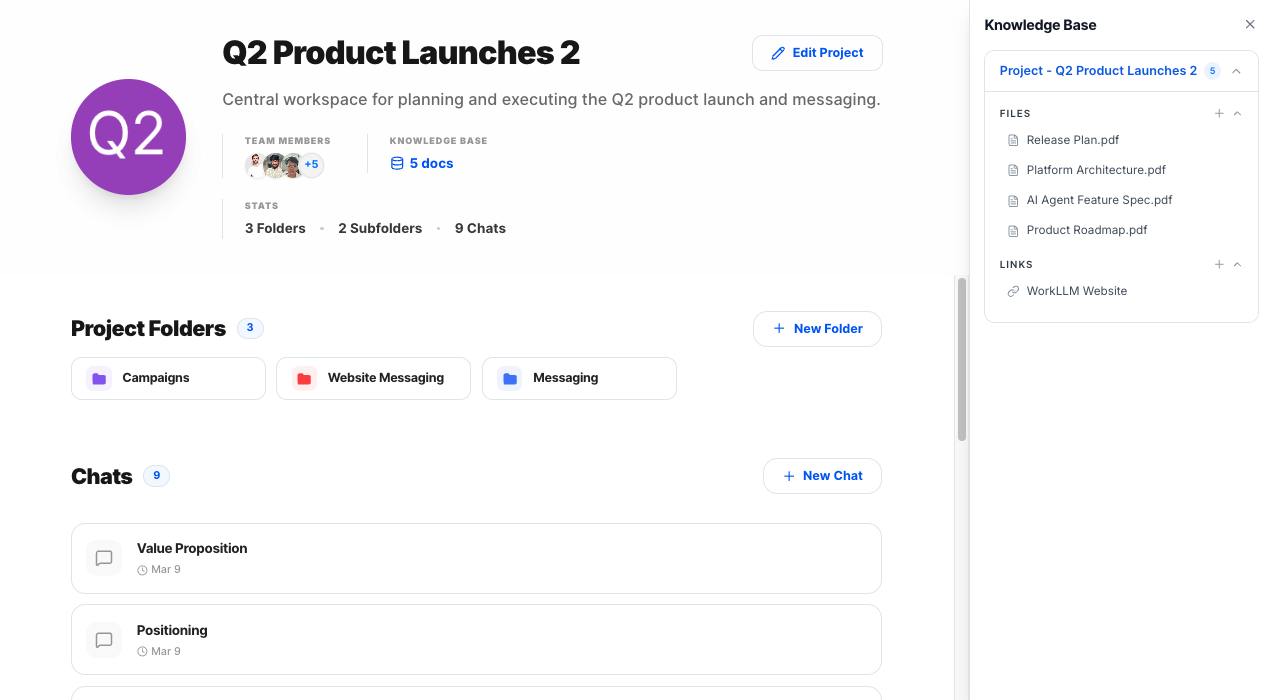
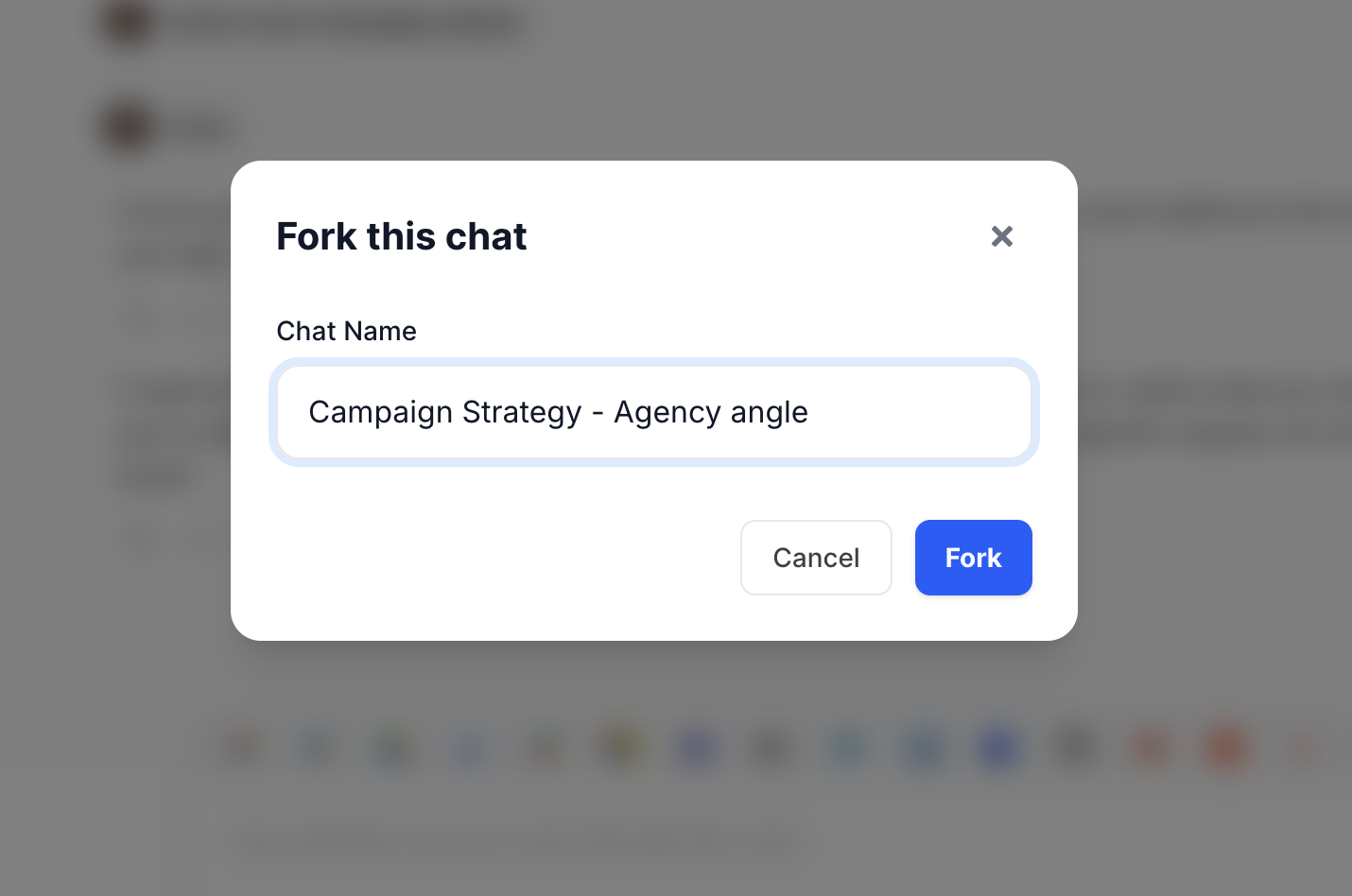
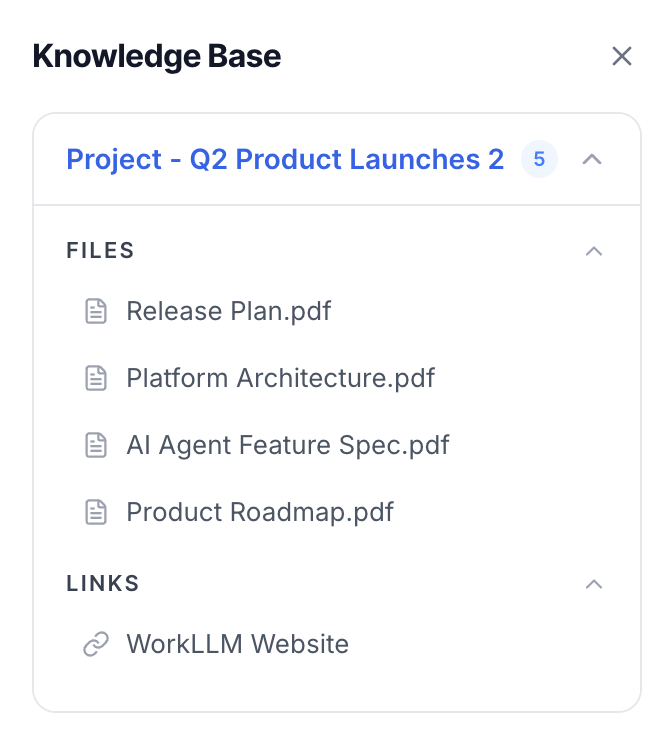
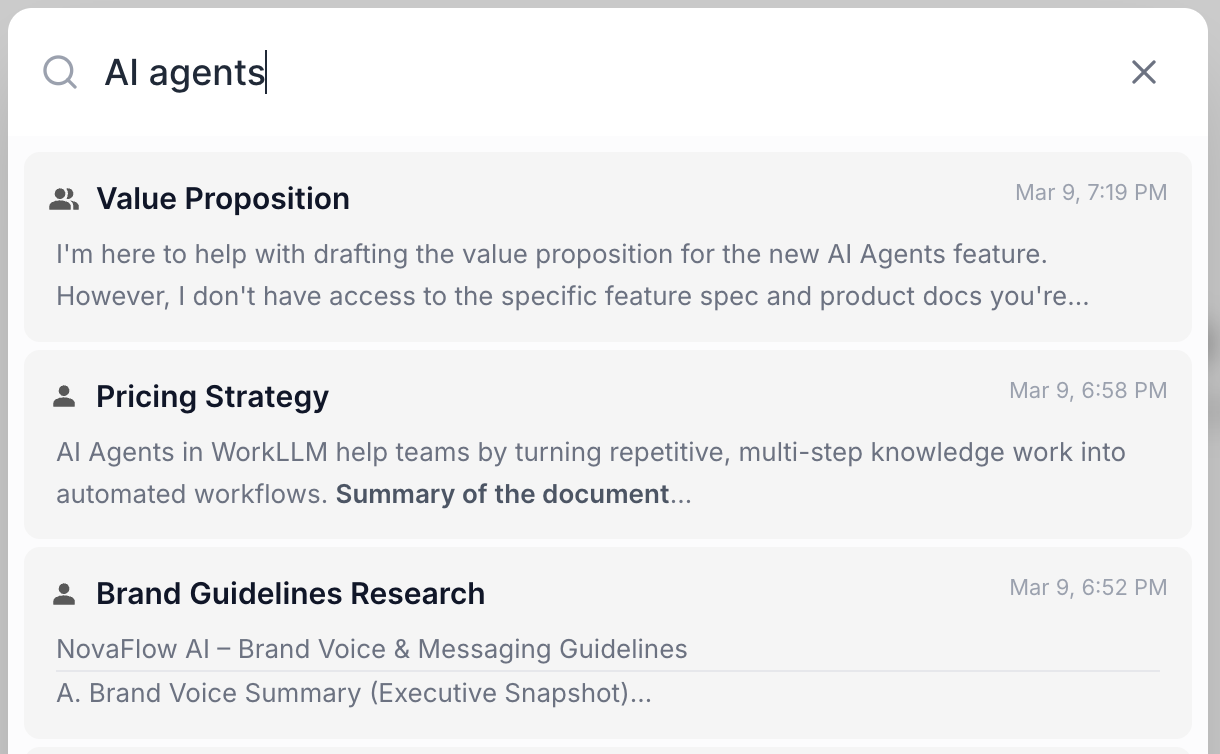
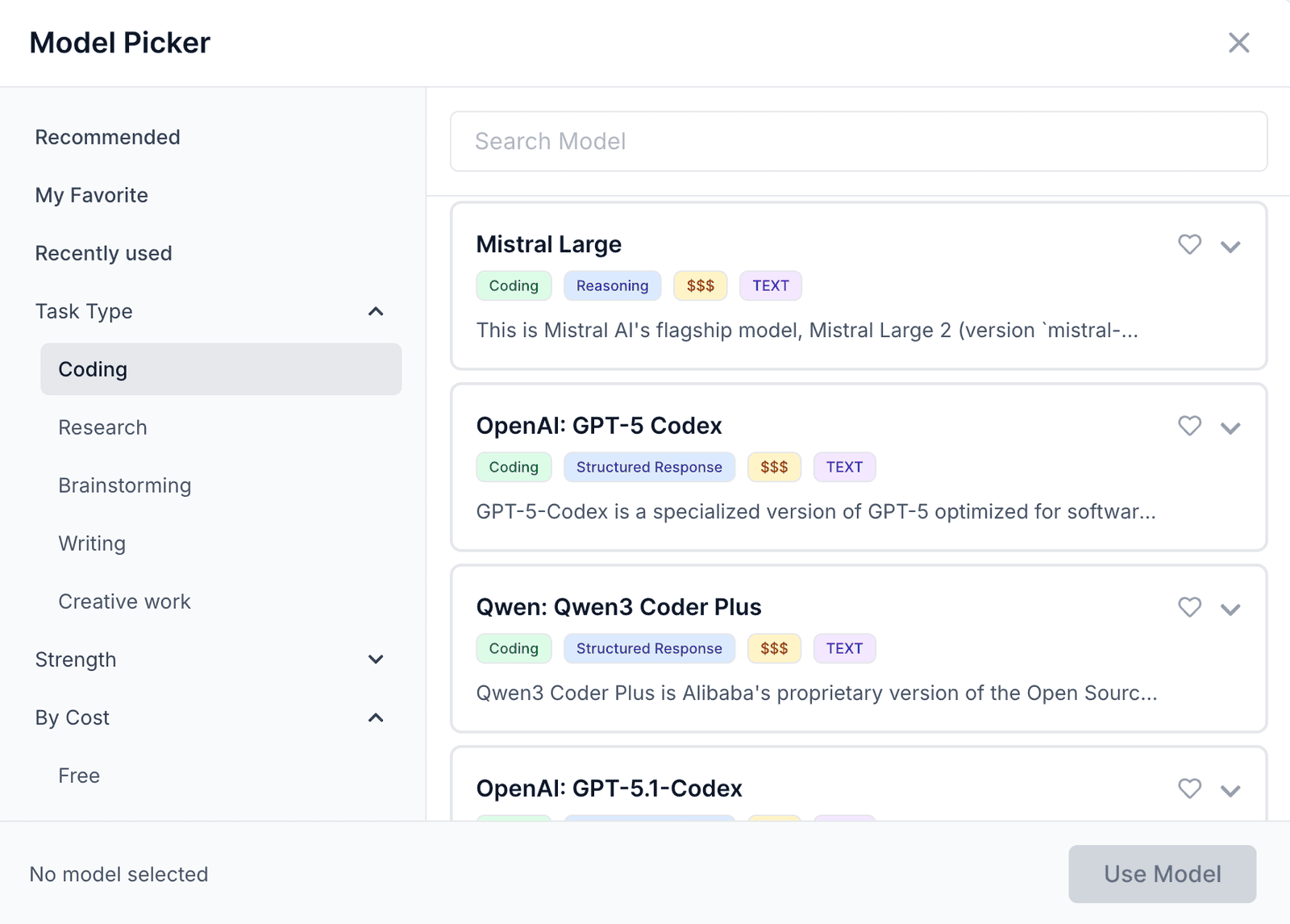
By Task Type
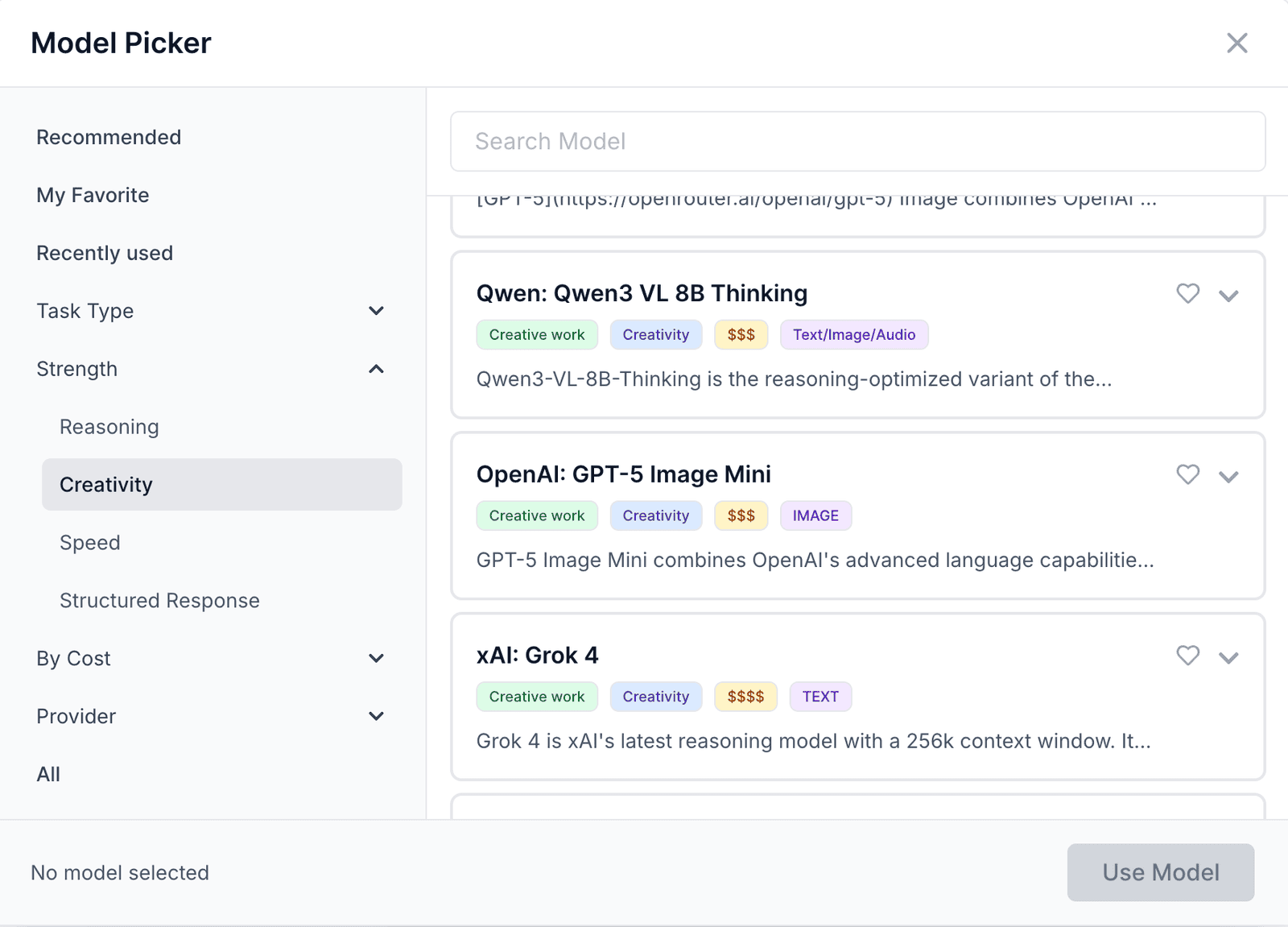
By Strength
By Cost
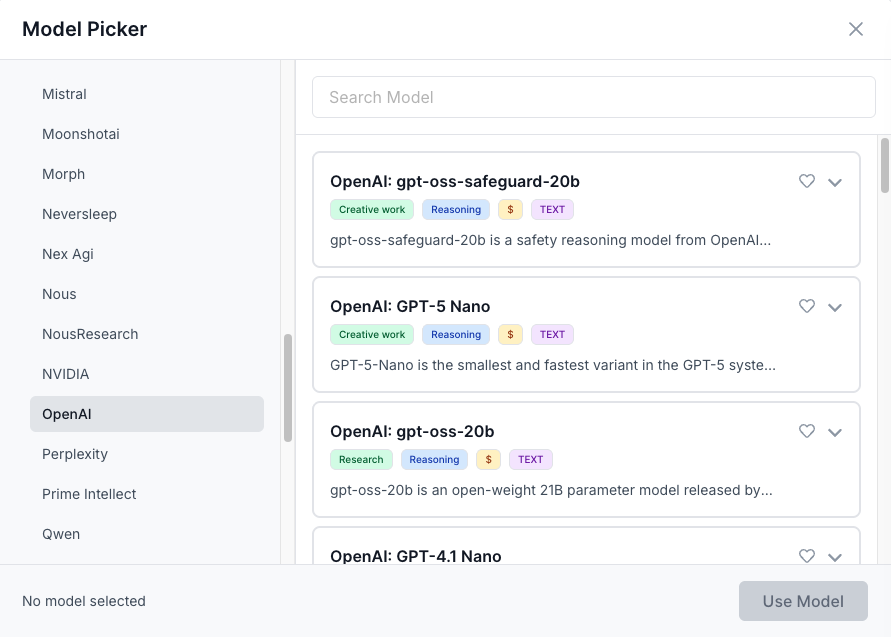
By Provider



“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Coriss Ambady
Financial Analyst ABC.com
“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Cory Zamora
Marketing Specialist ABC.com
“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Nikolas Brooten
Sales Specialist Financial Analyst ABC.com
“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Coriss Ambady
Financial Analyst Financial Analyst ABC.com
“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Jackie Sanders
Investment Planner Financial Analyst ABC.com
“Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Vestibulum id ligula porta felis euismod semper. Cras justo odio dapibus facilisis sociis natoque penatibus.”

Laura Widerski
Sales Specialist Financial Analyst ABC.com